2. How would you pass a Parent variable value to Child Package?We can pass the parent variable to child package by using Package configuration: Parent Package Variable.
2.1 Create parent variable FilePath - Parent - String - C:\RK\file.txt2.2 Drag an 'Execute Package Task' in Control Flow and configure it to start child package.
2.3 Go to Child Package and create a variable with same name as your parent package variable.2.4 Add Package configurations2.5 "Enable Package Configuration", choose Configuration type as "Parent Package Variable" and type the name of the variable.
2.6 click 'Next' button and select the 'Value' property of the child package variable.
2.7 click 'Next' and 'OK' buttons2.8 To test the package, I added sample Script Task with a messageBox to show the value of the parent package.
3. How to Generate an Auto Incremental Number in a SSIS Package?
A script component can be used for the designated task. The steps are as follows:
1. Drag and drop the Script Document to the Data flow and select the Script Component Type as Transformation.
2. Double click the Script Component.
3. Select the column which is to pass through the script component, in the Input Columns tab.
4. Add a column with an integer data type, in the Inputs and Outputs tab.
4. How to unzip a File in SSIS?
Use Execute Process Task in the Control Flow.
- From BIDS, drag and drop an "Execute Process Task" to the control flow and configure.
In the Execute Process, perform the following configurations:
-Executable: The path of the application that is being used.
-Arguments: Need to supply the arguments to extract the zipped files.
-Working Directory: The current directory for all process.
5. How to pass property value at Run time?
A property value like connection string for a Connection Manager can be passed to the packge using package configurations.
6. Will trigger fire when inserting data through SSIS package?
1.In the data flow task, go to the Advanced Editor of OLEDB Destination, and there should be a property "FastLoadOptions". Specify FIRE_TRIGGERS as an additional option.
3. Bulk Insert Task Editor:
7. How to deploy packages from one server to another server
1.To copy the deployment bundleLocate the deployment bundle on the first server.If you used the default location, the deployment bundle is the Bin\Deployment folder.Right-click the Deployment folder and click Copy.Locate the public share to which you want to copy the folder on the target computer and click Paste.2: Running the Package Installation Wizard1. On the destination computer, locate the deployment bundle.2. In the Deployment folder, double-click the manifest file, Project1.SSISDeploymentManifest.3. On the Welcome page of the Package Installation Wizard, click Next.4. On the Deploy SSIS Packages page, select either File sytem or SQL Server deployment option, select the "Validate packages after installation" check box, and then click Next.5. On the Specify Target SQL Server page, specify (local), in the Server name box.6. If the instance of SQL Server supports Windows Authentication, select Use Windows Authentication; otherwise, select Use SQL Server Authentication and provide a user name and a password.7. Verify that the "Rely on server storage for encryption" check box is cleared.Click Next.8. On the Select Installation Folder page, click Browse.9. On the Confirm Installation page, click Next.10. The wizard installs the packages. After installation is completed, the Configure Packages page opens.
8. What are the different types of Transaction Options
Required: If a transaction already exists at the upper level, the current executable will join the transaction. If No transaction at the upper level, a new transaction is created automatically.
Supported:In any executable, if there is a transaction at upper level, the executable join the transaction else do not create a new transaction.
Not Supported:The executable of the package do not honour any transaction ie do not join other transaction nor creates new transaction.
9. Explain about Checkpoints with properties
Checkpoint is used to restart the package execution from the point of failure rather than from initial start.
Set the following Properties:
CheckpointFileName: Specifies the name of the checkpoint file.
CheckpointUsage: Never, IfExists, Always
SaveCheckpoints: indicates whether the package needs to save checkpoints. This property must be set to True to restart a package from a point of failure.
FailPackageOnFailure: property needs to be set to True for enabling the task in the checkpoint.
Checkpoint mechanism uses a Text File to mark the point of package failure.
These checkpoint files are automatically created at a given location upon the package failure and automatically deleted once the package ends up with success.
10. How to execute SSIS Package from Stored Procedure.
using xp_cmdshell command
11. Parallel processing in SSIS
To support parallel execution of different tasks in the package, SSIS uses 2 properties:
1.MaxConcurrentExecutables: defines how many tasks can run simultaneously, by specifying the maximum number of SSIS threads that can execute in parallel per package. The default is -1, which equates to number of physical or logical processor + 2.
2. EngineThreads: is property of each DataFlow task. This property defines how many threads the data flow engine can create and run in parallel. The EngineThreads property applies equally to both the source threads that the data flow engine creates for sources and the worker threads that the engine creates for transformations and destinations. Therefore, setting EngineThreads to 10 means that the engine can create up to ten source threads and up to ten worker threads.
12. Package configuration? Different types of Configuration Files
The package can be transferred across various environments like development and unit testing, system testing, UAT and production. Most packages will have environment specific variables like connection string to a database or path to a flat file, or user defined variables etc. that would be impacted while moving the package across environments as part of deployment process. Hence, it is mandatory to change these environment dependent variables when the package is transferred across environments. Package configurations help in managing such changes without actually opening and editing the SSIS package in Business Intelligence Development Studio (BIDS). After deploying the package to a different machine (using SQL Server or file system deployment mode) it is mandatory to copy the related package configuration files on to that machine. If the package is scheduled to run through a SQL Agent job, the configuration file should be added while creating the job so that package will read the information from the configuration file. While executing the job, SQL Agent will take the design time values for connection strings if the package configuration file is not supplied.
There are 5 configuration types available with package configurations.
13. Logging. Different types of Logging files
Logging is used to log the information during the execution of package.
A log provider can be a text file, the SQL Server Profiler, a SQL Server relational database, a Windows event log, or an XML file. If necessary, you can define a custom log provider (e.g., a proprietary file format).
14. How to debug a package
For debugging a package, we have 3 options:-Setting breakpoints in a package, container or Task-Using Data Viewer in the Data flow task-Setting Error redirection in the Data Flow task
15. If the package fails, what steps u take
16. Error handling in SSIS package
I have created a package like below:
Select 'Load to sql Table' Data flow Task. Navigate to 'Even Handlers' Tab.
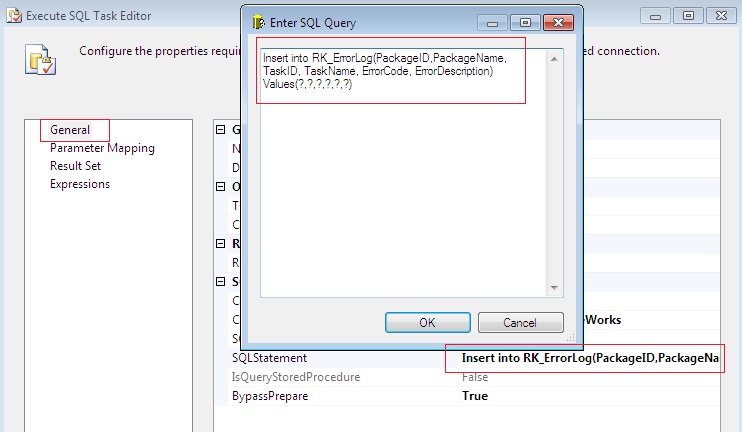
Drag and Drop 'Execute Sql Task'. Open the Execute Sql Task Editor and in Parameter Mapping' section, select the system variables as follows:
Create a table in Sql Server Database with Columns as: PackageID, PackageName, TaskID, TaskName, ErrorCode, ErrorDescription.
The package will be failed during the execution.
The error information is inserted into Table.
17. Difference between Merge and UnionAll TransformationsThe Union All transformation combines multiple inputs into one output. The transformation inputs are added to the transformation output one after the other; no reordering of rows occurs.
The Merge transformation combines two sorted datasets into a single dataset. The rows from each dataset are inserted into the output based on values in their key columns.The Merge transformation is similar to the Union All transformations. Use the Union All transformation instead of the Merge transformation in the following situations:
-The Source Input rows are not need to be sorted.
-The combined output does not need to be sorted.
-when we have more than 2 source inputs.
18. Multicast, Conditional Split, Bulk Insert Tasks
Multicast Transformation is used to extract output from single source and places onto multiple destinations.
Conditional Split transaformation is used for splitting the input data based on a specific condition. The condition is evaluated in VB Script.
Multicast Transformation generates exact copies of the source data, it means each recipient will have same number of records as the source whereas the Conditional Split Transformation divides the source data based on the defined conditions and if no rows match with this defined conditions those rows are put on default output.
Bulk Insert Task is used to copy the large volumn of data from text file to sql server destination.
19. Incremental Load in SSIS
Using Slowly Changing Dimension
Using Lookup and Cache Transformation
20. How to migrate Sql server 2005 Package to 2008 version
1. In BIDS, by right click on the "SSIS Packages" folder of an SSIS project and selecting "Upgrade All Packages".
2. Running "ssisupgrade.exe" from the command line (default physical location C:\Program Files\Microsoft SQL Server\100\DTS\Bin folder).
3. If you open a SSIS 2005 project in BIDS 2008, it will automatically launch the SSIS package upgrade wizard.
21. Difference between Synchronous and Asynchronous Transformation
Synchronous T/F process the input rows and passes them onto the data flow one row at a time.
When the output buffer of Transformation created a new buffer, then it is Asynchronous transformation. Output buffer or output rows are not sync with input buffer.
22. What are Row Transformations, Partially Blocking Transformation, Fully Blocking Transformation with examples.
In Row Transformation, each value is manipulated individually. In this transformation, the buffers can be re-used for other purposes like following:
OLEDB Datasource, OLEDB Data Destinations
Other Row transformation within the package, Other partially blocking transformations within the package.
examples of Row Transformations: Copy Column, Audit, Character Map
Partially Blocking Transformation:
These can re-use the buffer space allocated for available Row transformation and get new buffer space allocated exclusively for Transformation.
examples: Merge, Conditional Split, Multicast, Lookup, Import, Export Column
Fully Blocking Transformation:
It will make use of their own reserve buffer and will not share buffer space from other transformation or connection manager.
examples: Sort, Aggregate, Cache Transformation
23. Difference between FileSystem and Sql server Deployment
File System Deployment: We can save the package on a physical location on hard drive or any shared folder with this option, and we should provide a full qualified path to stored package in the FileSystem option.
Sql Server Deployment: SSIS packages will be stored in the sysssispackages table of MSDB Database.
24. Difference between Lookup and Fuzzy Lookup transformation
Lookup Transformation finds the exact match.
Fuzzy Lookup transformation matches input table with reference table. It finds the closest match and indicates the quality of the match.

25. Difference between Full Cache and Partial Cache
Partial Cache: The lookup cache starts off empty at the beginning of the data flow. When a new row comes in, the lookup transform checks its cache for the matching values. If no match is found, it queries the database. If the match is found at the database, the values are cached so they can be used the next time a matching row comes in.
Full Cache: The default cache mode for lookup is Full cache. The database is queried once during the pre-execute phase of the data flow. The entire reference set is pulled into memory. This approach uses most of the memory. Caching takes place before any rows are read from the data flow source. Lookup operations will be very fast during execution.
26. Cache Transformation
Cache Transformation: to cache the data used in the Lookup transform.When to use Full cache mode:When you're accessing a large portion of your reference setWhen you have a small reference tableWhen your database is remote or under heavy load, and you want to reduce the number of queries sent to the serverWhen to use Partial cache mode:When you're processing a small number of rows and it's not worth the time to charge the full cache.When you have a large reference table.When your data flow is adding new rows to your reference table.When you want to limit the size of your reference table by modifying query with parameters from the data flow.
27. Explain Slowly Changing Dimesnion
The SCD concept is basically about how the data modifications are absorbed and maintained in a Dimension Table.
The new (modified) record and the old record(s) are identified using some kind of a flag like say IsActive, IsDeleted etc. or using Start and End Date fields to
indicate the validity of the record.
Types:
Type 1 - update the columns in the dimension row without preserving any change history.Type 2 - preserve the change history in the dimension table and create a new row when there are changes. Type 3 - some combination of Type 1 and Type 2, usually maintaining multiple instances of a column in the dimension row; e.g. a current value and one or more previous values.
28. Different types of File Enumerators
Foreach ADO: The ADO Enumerator enumerates rows in a table. For example, we can get the rows in the ADO records.The variable must be of Object data type.Foreach ADO.NET Schema Rowset: The ADO.Net Enumerator enumerates the schema information. For example, we can get the table from the database.Foreach File: The File Enumerator enumerates files in a folder. For example, we can get all the files which have the *.txt extension in a windows folder and its sub folders.Foreach From Variable: The Variable Enumerator enumerates objects that specified variables contain. Here enumerator objects are nothing but an array or data table.Foreach Item: The Item Enumerator enumerates the collections. For example, we can enumerate the names of executables and working directories that an “Execute Process” task uses.Foreach Nodelist: The Node List Enumerator enumerates the result of an XPath expression.Foreach SMO: The SMO Enumerator enumerates SQL Server Management Objects (SMO). For example, we can get the list of functions or views in a SQL Server database.
29. How to execute a package from Dotnet application
30. How to schedule a package (Role of Sql Server Agent)In order for the job to run successfully, the SQL Server agent should be running on the target machine. We can start the SQL Server Agent Services in numerous ways like:-
- Starting SQL Server Agent Service from Command Line
- Starting SQL Server Agent Service from Services.MSC console
- Starting SQL Server Agent Service using SQL Server Configuration Manager
- Starting SQL Server Agent Service using SQL Server Management Studio (SSMS)
31. What are containers? (For loop, Sequence Container)
SSIS Containers are controls that provide structure to SSIS packages. Containers support repeating control flows in packages and they group tasks and containers into meaningful units of work. Containers can include other containers in addition to tasks.
| Container Type | Container Description | Purpose of SSIS Container |
|---|
| Foreach Loop Container | This container runs a Control Flow repeatedly using an enumerator. | To repeat tasks for each element in a collection, for example retrieve files from a folder, running T-SQL statements that reside in multiple files, or running a command for multiple objects. |
| For Loop Container | This container runs a Control Flow repeatedly by checking conditional expression (same as For Loop in programming language). | To repeat tasks until a specified expression evaluates to false. For example, a package can send a different e-mail message seven times, one time for every day of the week. |
| Sequence Container | Groups tasks as well as containers into Control Flows that are subsets of the package Control Flow. | This container group tasks and containers that must succeed or fail as a unit. For example, a package can group tasks that delete and add rows in a database table, and then commit or roll back all the tasks when one fails. |
32. What are precedence constraints
A task will only execute if the condition that is set by the precedence constraint preceding the task is met. By using these constraints,it will choose different execution paths depending on the success or failure of other tasks.
Success – Workflow will proceed when the preceding container executes successfully. Indicated in control flow by a solid green line.Failure – Workflow will proceed when the preceding container’s execution results in a failure. Indicated in control flow by a solid red line.Completion – Workflow will proceed when the preceding container’s execution completes, regardless of success or failure. Indicated in control flow by a solid blue line.Expression/Constraint with Logical AND – Workflow will proceed when specified expression and constraints evaluate to true. Indicated in control flow by a solid color line along with a small ‘fx’ icon next to it. Color of line depends on logical constraint chosen (e.g. success=green, completion=blue).Expression/Constraint with Logical OR – Workflow will proceed when either the specified expression or the logical constraint (success/failure/completion) evaluates to true. Indicated in control flow by a dotted color line along with a small ‘fx’ icon next to it. Color of line depends on logical constraint chosen (e.g. success=green, completion=blue).
33. Performance Optimization in SSIS
1. Avoid Asynchronous Transformation (Sort T/F) wherever possible. Sort T/F required all the incoming rows to be arrivaed before start processing. Instead of using Sort T/F, we get sorted rows from datasource using ORDER By clause.
2. Pulling High Volumes of Data
Drop all Non-Clustered Indexes and Clustered Index if exists, then Transfer and load the data into Destination Table. Create Clustered Index and Non-clustered indexes.
3. Avoid SELECT *
DataFlow Task uses buffer oriented architecture for data transfer and transformation. When data transfer from Source to Destination, the data first comes into the buffer, required transformations are done in the buffer itself and then written to Destination.
The size of buffer depends on the estimated row size. The estimated row size is equal to the maximum size of all columns in the row. So the more columns in a row means less number of rows in a buffer. Hence select only those columns which are required at the destination.
Even if we need all the columns from source, we should use the column name specifically in the SELECT statement, otherwise it takes another round for the source to gather meta-data about the columns when u are using SELECT *.
4. Effect of OLEDB Destination Settings
There are couple of settings with OLEDB destination which can impact the performance of data transfer as listed below.
Data Access Mode – This setting provides the 'fast load' option which internally uses a BULK INSERT statement for uploading data into the destination table instead of a simple INSERT statement (for each single row) as in the case for other options. So unless you have a reason for changing it, don't change this default value of fast load. If you select the 'fast load' option, there are also a couple of other settings which you can use as discussed below.
Keep Identity – By default this setting is unchecked which means the destination table (if it has an identity column) will create identity values on its own. If you check this setting, the dataflow engine will ensure that the source identity values are preserved and same value is inserted into the destination table.
Keep Nulls – Again by default this setting is unchecked which means default value will be inserted (if the default constraint is defined on the target column) during insert into the destination table if NULL value is coming from the source for that particular column. If you check this option then default constraint on the destination table's column will be ignored and preserved NULL of the source column will be inserted into the destination.
Table Lock – By default this setting is checked and the recommendation is to let it be checked unless the same table is being used by some other process at same time. It specifies a table lock will be acquired on the destination table instead of acquiring multiple row level locks, which could turn into lock escalation problems.
Check Constraints – Again by default this setting is checked and recommendation is to un-check it if you are sure that the incoming data is not going to violate constraints of the destination table. This setting specifies that the dataflow pipeline engine will validate the incoming data against the constraints of target table. If you un-check this option it will improve the performance of the data load.
#5 - Effect of Rows Per Batch and Maximum Insert Commit Size Settings:
Rows per batch:
The default value for this setting is -1 which specifies all incoming rows will be treated as a single batch. You can change this default behavior and break all incoming rows into multiple batches. The allowed value is only positive integer which specifies the maximum number of rows in a batch.
Maximum insert commit size:
The default value for this setting is '2147483647' (largest value for 4 byte integer type) which specifies all incoming rows will be committed once on successful completion. You can specify a positive value for this setting to indicate that commit will be done for those number of records. Changing the default value for this setting will put overhead on the dataflow engine to commit several times. Yes that is true, but at the same time it will release the pressure on the transaction log and tempdb to grow specifically during high volume data transfers.
The above two settings are very important to understand to improve the performance of tempdb and the transaction log. For example if you leave 'Max insert commit size' to its default, the transaction log and tempdb will keep on growing during the extraction process and if you are transferring a high volume of data the tempdb will soon run out of memory as a result of this your extraction will fail. So it is recommended to set these values to an optimum value based on your environment.
#7 - DefaultBufferSize and DefaultBufferMaxRows :
The execution tree creates buffers for storing incoming rows and performing transformations.
The number of buffer created is dependent on how many rows fit into a buffer and how many rows fit into a buffer dependent on few other factors. The first consideration is the estimated row size, which is the sum of the maximum sizes of all the columns from the incoming records. The second consideration is the DefaultBufferMaxSize property of the data flow task. This property specifies the default maximum size of a buffer. The default value is 10 MB and its upper and lower boundaries are constrained by two internal properties of SSIS which are MaxBufferSize (100MB) and MinBufferSize (64 KB). It means the size of a buffer can be as small as 64 KB and as large as 100 MB. The third factor is, DefaultBufferMaxRows which is again a property of data flow task which specifies the default number of rows in a buffer. Its default value is 10000.
If the size exceeds the DefaultBufferMaxSize then it reduces the rows in the buffer. For better buffer performance you can do two things.
First you can remove unwanted columns from the source and set data type in each column appropriately, especially if your source is flat file. This will enable you to accommodate as many rows as possible in the buffer.
Second, if your system has sufficient memory available, you can tune these properties to have a small number of large buffers, which could improve performance. Beware if you change the values of these properties to a point where page spooling (see Best Practices #8) begins, it adversely impacts performance. So before you set a value for these properties, first thoroughly testing in your environment and set the values appropriately.
#8 - How DelayValidation property can help you
SSIS uses two types of validation.
First is package validation (early validation) which validates the package and all its components before starting the execution of the package.
Second SSIS uses component validation (late validation), which validates the components of the package once started.
Let's consider a scenario where the first component of the package creates an object i.e. a temporary table, which is being referenced by the second component of the package. During package validation, the first component has not yet executed, so no object has been created causing a package validation failure when validating the second component. SSIS will throw a validation exception and will not start the package execution. So how will you get this package running in this common scenario?
To help you in this scenario, every component has a DelayValidation (default=FALSE) property. If you set it to TRUE, early validation will be skipped and the component will be validated only at the component level (late validation) which is during package execution
9. Better performance with parallel execution10. When to use events logging and when to avoid.
11. Monitoring the SSIS Performance with Performance CountersLaunch Performance Monitor:1. Start -> All Programs -> Administrative Tools -> Performance2. Load the SSIS related CountersIn the Performance Object, select SQL Server:SSIS Pipeline and SQL Server:SSIS Service.
SSIS provide a set of performance counters. Among them, the following few are helpful when you tune or debug your package:Buffers in useFlat buffers in usePrivate buffers in useBuffers spooledRows readRows written
“Buffers in use”, “Flat buffers in use” and “Private buffers in use” are useful to discover leaks. During package execution time, we will see these counters fluctuating. But once the package finishes execution, their values should return to the same value as what they were before the execution. Otherwise, buffers are leaked.
“Buffers spooled” has an initial value of 0. When it goes above 0, it indicates that the engine has started memory swapping. In a case like this, set Data Flow Task properties BLOBTempStoragePath and BufferTempStoragePath appropriately for maximal I/O bandwidth.Buffers Spooled: The number of buffers currently written to the disk. If the data flow engine runs low on physical memory, buffers not currently used are written to disk and then reloaded when needed.
“Rows read” and “Rows written” show how many rows the entire Data Flow has processed.
12. FastParse propertyFast Parse option in SSIS can be used for very fast loading of flat file data. It will speed up parsing of integer, date and time types if the conversion does not have to be locale-sensitive. This option is set on a per-column basis using the Advanced Editor for the flat file source.
13. Checkpoint features helps in package restarting
34. Upgrade DTS package to SSIS
1. In BIDS, from the Project Menu, select 'Migrate DTS 2000 Package'
2. In the Package Migration Wizard, choose the Source, Sql Server 2000 Server Name, Destination folder.
3. Select the List of packages that needs to be upgraded to SSIS
4. Specifty the Log file for Package Migration.
35. Events in SSIS
OnError : Runs when a task or container reports an error.
OnExecStatusChanged : Runs for all tasks and containers when the execution status changes to In Process, Success, or Failed.
OnInformation : Runs when SSIS outputs information messages during the validation and execution of a task or container.
OnPostExecute : Runs after a container or task successfully completes.
OnPostValidate : Executes after a container or task has successfully been validated.
OnPreExecute : Runs just before a container or task is executed.
OnPreValidate: Runs before the component is validated by the engine.
OnProgress : Executed when a progress message is sent by the SSIS engine, indicating tangible advancement of the task or container.
OnQueryCancel : Invoked when an Execute SQL Task is cancelled through manual intervention, such as stopping the package.
OnTaskFailed : Similar to OnError, but runs when a task fails rather than each time an error occurs.
OnVariableValueChanged: Runs when the value changes in a variable for which the RaiseChangeEvent property is set to True.
OnWarning Runs: when a task returns a warning event such as a column not being used in a data flow.
36. Difference between Control Flow and Data Flow
1.Control flow consists of one or more tasks and containers that execute when the package runs. We use precedence constraints to connect the tasks and containers in a package. SSIS provides three different types of control flow elements: Containers that provide structures in packages, Tasks that provide functionality, and Precedence Constraints that connect the executables, containers, and tasks into an ordered control flow.
2.Control flow does not move data from task to task.
3.Tasks are run in series if connected with precedence or in parallel.
1. A data flow consists of the sources and destinations that extract and load data, the transformations that modify and extend data, and the paths that link sources, transformations, and destinations. The Data Flow task is the executable within the SSIS package that creates, orders, and runs the data flow. Data Sources, Transformations, and Data Destinations are the three important categories in the Data Flow.
2. Data flows move data, but there are also tasks in the control flow, as such, their success or Failure effects how your control flow operates
3. Data is moved and manipulated through transformations.
4. Data is passed between each component in the data flow.
37. Different ways to execute SSIS package1. Using the Execute Package Utility (DTEXECUI.EXE) graphical interface one can execute an SSIS package that is stored in a File System, SQL Server or an SSIS Package Store.
DTEXECUI provides a graphical user interface that can be used to specify the various options to be set when executing an SSIS package. You can launch DTEXECUI by double-clicking on an SSIS package file (.dtsx). You can also launch DTEXECUI from a Command Prompt then specify the package to execute.
2. Using the DTEXEC.EXE command line utility one can execute an SSIS package that is stored in a File System, SQL Server or an SSIS Package Store. The syntax to execute a SSIS package which is stored in a File System is shown below.
DTEXEC.EXE /F "C:\BulkInsert\BulkInsertTask.dtsx"
3. Test the SSIS package execution by running the package from BIDS:
-In Solution Explorer, right click the SSIS project folder that contains the package which you want to run and then click properties.
- In the SSIS Property Pages dialog box, select Build option under the Configuration Properties node and in the right side panel, provide the folder location where you want the SSIS package to be deployed within the OutputPath. Click OK to save the changes in the property page.
-Right click the package within Solution Explorer and select Execute Package option from the drop down menu
4. Sql Server Agent:
Drill down to the SQL Server Agent node in the Object Explorer. Right click on the Jobs node and select New Job from the popup menu.
The first step to setting up the proxy is to create a credential (alternatively you could use an existing credential). Navigate to Security then Credentials in SSMS Object Explorer and right click to create a new credential
Navigate to SQL Server Agent then Proxies in SSMS Object Explorer and right click to create a new proxy
38. How to execute a Stored Procedure from SSIS
using Execute SQL Task
39. What are the different types of Transformations you have worked
AGGEGATE -The Aggregate transformation applies aggregate functions to column values and copies the results to the transformation output. Besides aggregate functions, the transformation provides the GROUP BY clause, which you can use to specify groups to aggregate across.The Aggregate Transformation supports following operations:Group By, Sum, Average, Count, Count Distinct, Minimum, Maximum
AUDIT - Adds Package and Task level Metadata - such as Machine Name, Execution Instance, Package Name, Package ID, etc..
CHARACTER MAP - When it comes to string formatting in SSIS, Character Map transformation is very useful, used to convert data lower case, upper case.
CONDITIONAL SPLIT – used to split the input source data based on condition.
COPY COLUMN - Add a copy of column to the output, we can later transform the copy keeping the original for auditing.
DATA CONVERSION - Converts columns data types from one to another type. It stands for Explicit Column Conversion.
DATA MINING QUERY – Used to perform data mining query against analysis services and manage Predictions Graphs and Controls.
DERIVED COLUMN - Create a new (computed) column from given expressions.
EXPORT COLUMN – Used to export a Image specific column from the database to a flat file.
FUZZY GROUPING – Groups the rows in the dataset that contain similar values.
FUZZY LOOKUP - Used for Pattern Matching and Ranking based on fuzzy logic.
IMPORT COLUMN - Reads image specific column from database onto a flat file.
LOOKUP - Performs the lookup (searching) of a given reference object set against a data source. It is used for exact matches only.
MERGE - Merges two sorted data sets of same column structure into a single output.
MERGE JOIN - Merges two sorted data sets into a single dataset using a join.
MULTI CAST - is used to create/distribute exact copies of the source dataset to one or more destination datasets.
ROW COUNT - Stores the resulting row count from the data flow / transformation into a variable.
ROW SAMPLING - Captures sample data by using a row count of the total rows in dataflow specified by rows or percentage.
UNION ALL - Merge multiple data sets into a single dataset.
PIVOT – Used for Normalization of data sources to reduce analomolies by converting rows into columns
UNPIVOT – Used for demoralizing the data structure by converts columns into rows incase of building Data Warehouses.
40. How to deploy a package
Right click on the Solution in Solution Explorer and choose properties in the Menu.


When the build /rebuild is successful, navigate to the directory is referred in DeploymentOutputPathDeploying the Package:Double click the Manifest File to start the deployment. The Package Installation wizard begins and Deploy SSIS Packages step is the first screen that is presented. This screen lets you select where shall the packages be deployed, as mentioned in the Dialog Box, deploying in SQL Server is more secure, since SQL Server stores the packages internally compared to File System where additional security measures needs to taken to secure the physical files.
This screen lets you select where shall the packages be deployed, as mentioned in the Dialog Box, deploying in SQL Server is more secure, since SQL Server stores the packages internally compared to File System where additional security measures needs to taken to secure the physical files. 


41. What is the use of Percentage Sampling transformation in SSIS?
Percentage Sampling transformation is generally used for data mining. This transformation builds a random sample of set of output rows by choosing specified percentage of input rows. For example if the input has 1000 rows and if I specify 10 as percentage sample then the transformation returns 10% of the RANDOM records from the input data.
42. What is the use of Term Extraction transformation in SSIS?
Term Extraction transformation is used to extract nouns or noun phrases or both noun and noun phrases only from English text. It extracts terms from text in a transformation input column and then writes the terms to a transformation output column. It can be also used to find out the content of a dataset.
43. What is Data Viewer and what are the different types of Data Viewers in SSIS?
A Data Viewer allows viewing data at a point of time at runtime.
The different types of data viewers are:
1. Grid
2. Histogram
3. Scatter Plot
44. What is Ignore Failure option in SSIS?
In Ignore Failure option, the error will be ignored and the data row will be directed to continue on the next transformation. Let’s say you have some JUNK data(wrong type of data ) flowing from source, then using this option in SSIS we can REDIRECT the junk data records to another transformation instead of FAILING the package. This helps to MOVE only valid data to destination and JUNK can be captured into separate file.
45. How do we convert data type in SSIS?
The Data Conversion Transformation in SSIS converts the data type of an input column to a different data type.
46. Explain Audit Transformation ?
It allows you to add auditing information. Auditing options that you can add to transformed data through this transformation are :
1. Execution of Instance GUID : ID of execution instance of the package
2. PackageID : ID of the package
3. PackageName : Name of the Package
4. VersionID : GUID version of the package
5. Execution StartTime
6. MachineName
7. UserName
8. TaskName
9. TaskID : unique identifier type of the data flow task that contains audit transformation.
47. what are the possible locations to save SSIS package?
1.File System: We can save the package on a physical location on hard drive or any shared folder with this option, and we should provide a full qualified path to stored package in the FileSystem option.
2. Sql Server: SSIS packages will be stored in the MSDB database, in the sysssispackages table.
SSIS Package Store is nothing but combination of SQL Server and File System deployment, as you can see when you connect to SSIS through SSMS: it looks like a store which has categorized its contents (packages) into different categories based on its manager’s (which is you, as the package developer) taste. So, don’t get it wrong as something different from the 2 types of package deployment.
48. How to provide security to packages?
We can provide security to packages in 2 ways
1. Package encryption
1. DonotSaveSensitive: any sensitive information is simply not written out to the package XML file when you save the package.
2. EncryptSensitiveWithUserKey: encrypts sensitive information based on the credentials of the user who created the package. It is the default value for the ProtectionLevel property.
3. EncryptSensitiveWithPassword: requires to specify a password in the package, and this password will be used to encrypt and decrypt the sensitive information in the package.
4. EncryptAllWithPassword: allows to encrypt the entire contents of the SSIS package with your specified password.
5. EncryptAllWithUserKey: allows to encrypt the entire contents of the SSIS package by using the user key.
6. Server Storage: allows the package to retain all sensitive information when you are saving the package to SQL Server. SSIS packages are saved to MSDB database of SQL Server.
You can change the Protection Level of deployed packages by using the DTUTIL utility.
49. How to track a variable in ssis?
OnVariableValueChanged: This event gets raised when value of the variable is changed.
1.Set the "EvaluateasExpression" property of the variable as True.
2.Set the "RaiseChangedEvent" property of the variable as True.
3.Create an event handler for the "OnVariableValueChanged" event for the container in which the variable is scoped.
50. FTP Task:
The FTP task downloads and uploads data files and manages directories on servers. For example, a package can download data files from a remote server.
use the FTP task for the following purposes:1. Copying directories and data files from one directory to another, before or after moving data, and applying transformations to the data.2. Downloading files from an FTP location and applying transformations to column data before loading the data into a database.
At run time, the FTP task connects to a server by using an FTP connection manager. The FTP connection manager includes the server settings, the credentials for accessing the FTP server, and options such as the time-out and the number of retries for connecting to the server.
The FTP connection manager supports only anonymous authentication and basic authentication. It does not support Windows Authentication.Predefined FTP Operations:Send Files, Receive File, Create Local directory, Remove Local Directory,Create Remote Directory, Remove Remote DirectoryDelete Local Files, Delete Remote FileCustomer Log Entries available on FTP Task:FTPConnectingToServerFTPOperation
51. New features in SSIS 20121. GUI Improvements - -Sort packages by name -Package visualization -Zoom -Data flow source/destination wizard -Grouping in data flow
2. CDC (Change Data Capture) Task and Components - -CDC is nothing but Incremental load loads all rows that have changed since the last load -CDC needs to keep track of which changes have already been processed. -CDC task does this by storing LSNs in a tracking table -CDC source component reads from the CDC table function, based on the LSN it for from the CDC task. -CDC transformation splits records into new rows, updated rows and deleted rows.
3. Flat File Connection Manager Changes - -The Flat File connection manager now supports parsing files with embedded qualifiers. The connection manager also by default always checks for row delimiters to enable the correct parsing of files with rows that are missing column fields. The Flat File Source now supports a varying number of columns, and embedded qualifiers.
4. Offline Connection Managers - -Integration Services now validates all connections before validating all of the data flow components when a package is opened and sets any connections that are slow or unavailable to work offline. This helps to reduce the delay in validating the package data flow. After a package is opened, you can also turn off a connection by right-clicking the connection manager in the Connection Managers area and then clicking Work Offline. This can speed up operations in the SSIS Designer.
5. New Functions/Expressions in SSIS 2012-
LEFT: You now can easily return the leftmost portion of a string rather than use the SUBSTRING function. Left syntax is the same as we know in T-SQL: LEFT(character_expression,number)
REPLACENULL: You can use this function to replace NULL values in the first argument with the expression specified in the second argument. This is equivalent to ISNULL in T-SQL: REPLACENULL(expression, expression)
TOKEN: This function allows you to return a substring by using delimiters to separate a string into tokens and then specifying which occurrence to return: TOKEN(character_expression, delimiter_string, occurrence)
TOKENCOUNT: This function uses delimiters to separate a string into tokens and then returns the count of tokens found within the string: TOKENCOUNT(character_expression, delimiter_string)
6. Easy Column Remapping in Data Flow (Mapping Data Flow Columns) -When modifying a data flow, column remapping is sometimes needed -SSIS 2012 maps columns on name instead of id -It also has an improved remapping dialog
7. Shared Connection Managers - To create connection managers at the project level that can shared by multiple packages in the project. The connection manager you create at the project level is automatically visible in the Connection Managers tab of the SSIS Designer window for all packages. -When converting shared connection managers back to regular (package) connection managers, they disappear in all other packages.
8. Scripting Enhancements- -Now Script task and Script Component support for 4.0. - Breakpoints are supported in Script Component
9. ODBC Source and Destination - -ODBC was not natively supported in 2008 -SSIS 2012 has ODBC source & destination -SSIS 2008 could access ODBC via ADO.NET
10. Reduced Memory Usage by the Merge and Merge Join Transformations – The old SSIS Merge and Merge Join transformations, although helpful, used a lot of system resources and could be a memory hog. In 2012 these tasks are much more robust and reliable. Most importantly, they will not consume excessive memory when the multiple inputs produce data at uneven rates.
11. Undo/Redo - One thing that annoys users in SSIS before 2012 is lack of support of Undo and Redo. Once you performed an operation, you can’t undo that. Now in SSIS 2012, we can see the support of undo/redo.
52. Difference between Script Task and Script Component in SSIS.
| Script Task | Script Component |
| Control Flow/Date Flow | The Script task is configured on the Control Flow tab of the designer and runs outside the data flow of the package. | The Script component is configured on the Data Flow page of the designer and represents a source, transformation, or destination in the Data Flow task. |
| Purpose | A Script task can accomplish almost any general-purpose task. | You must specify whether you want to create a source, transformation, or destination with the Script component. |
| Raising Results | The Script task uses both the TaskResult property and the optional ExecutionValue property of the Dts object to notify the runtime of its results. | The Script component runs as a part of the Data Flow task and does not report results using either of these properties. |
| Raising Events | The Script task uses the Events property of the Dts object to raise events. For example: Dts.Events.FireError(0, "Event Snippet", ex.Message & ControlChars.CrLf & ex.StackTrace | The Script component raises errors, warnings, and informational messages by using the methods of the IDTSComponentMetaData100 interface returned by the ComponentMetaData property. For example: Dim myMetadata as IDTSComponentMetaData100
myMetaData = Me.ComponentMetaData
myMetaData.FireError(...) |
| Execution | A Script task runs custom code at some point in the package workflow. Unless you put it in a loop container or an event handler, it only runs once. | A Script component also runs once, but typically it runs its main processing routine once for each row of data in the data flow. |
| Editor | The Script Task Editor has three pages: General, Script, and Expressions. Only the ReadOnlyVariables and ReadWriteVariables, and ScriptLanguage properties directly affect the code that you can write. | The Script Transformation Editor has up to four pages: Input Columns, Inputs and Outputs, Script, and Connection Managers. The metadata and properties that you configure on each of these pages determines the members of the base classes that are autogenerated for your use in coding. |
| Interaction with the Package | In the code written for a Script task, you use the Dts property to access other features of the package. The Dts property is a member of the ScriptMain class. | In Script component code, you use typed accessor properties to access certain package features such as variables and connection managers. The PreExecute method can access only read-only variables. The PostExecute method can access both read-only and read/write variables. |
| Using Variables | The Script task uses the Variables property of the Dts object to access variables that are available through the task’s ReadOnlyVariables and ReadWriteVariables properties. For example: string myVar; myVar = Dts.Variables["MyStringVariable"].Value.ToString(); | The Script component uses typed accessor properties of the autogenerated based class, created from the component’s ReadOnlyVariables and ReadWriteVariables properties. For example: string myVar; myVar = this.Variables.MyStringVariable; |
| Using Connections | The Script task uses the Connections property of the Dts object to access connection managers defined in the package. For example: string myFlatFileConnection; myFlatFileConnection = (Dts.Connections["Test Flat File Connection"].AcquireConnection(Dts.Transaction) as String); | The Script component uses typed accessor properties of the autogenerated base class, created from the list of connection managers entered by the user on the Connection Managers page of the editor. For example: IDTSConnectionManager100 connMgr;connMgr = this.Connections.MyADONETConnection; |
53.Difference between DTS and SSIS?
DTS:
Limited number of transformations.
Limited error handling.
Message box in active-x scripts.
SSIS:
More number of transformations.
Better error handling.
Message box in .NET scripting.
54. How to execute package from command line
1. To execute an SSIS package saved to SQL Server using Windows Authentication: dtexec /sq pkgOne /ser productionServer2. To execute an SSIS package that is saved in the file system: dtexec /f "c:\pkgOne.dtsx" 3. To execute an SSIS package saved to the File System folder in the SSIS Package Store: dtexec /dts "\File System\MyPackage"4. To execute an SSIS package that is saved in the file system and configured externally: dtexec /f "c:\pkgOne.dtsx" /conf "c:\pkgOneConfig.cfg"
55. How to execute the package from .NET?We need a reference to Microsoft.SqlServer.ManagedDts.dll to call a package.
using Microsoft.SqlServer.Dts.RuntimeApplication app = new Application();Package package = null;package = app.LoadPackage(@"C:\Program Files\Microsoft SQL Server\100\DTS\Packages\Integration Services Project2\Package.dtsx", null);Microsoft.SqlServer.Dts.Runtime.DTSExecResult results = package.Execute();
56. which service requires to start a job SQL Server Agent Service57. OLEDB Destination, SQL Destination, Bulk Insert1. OLEDB destination loads the records in batches, where as SQL Server destination loads all the records at one go. 2. OLEDB Destination uses the 'Fast Load' data access mode.SQL Server destination uses shared memory for maximum loading speed, must execute on the same server as the database engine.Prefer the OLE-DB Destination simply because it gives better flexibility on where you execute the package.
3. The Bulk Insert task uses the T-SQL BULK INSERT statement for speed when loading large amounts of data.58.which services are installed during Sql Server installationSSISSSASSSRSSQL Server (MSSQLSERVER)SQL Server Agent ServiceSQL Server BrowserSQL Full-Text
59. How to run dynamic T-SQL in SSIS?
Option#1: Using Script Component as Destination
Option#2: Using Object Variable and run t-sql with Execute SQL Task
60. What is the use of RecordSet Destination?
The Recordset destination does not save data to an external data source. Instead, it saves data in memory in a recordset that is stored in variable of the Object data type. After the Recordset destination saves the data, we use a Foreach Loop container with the Foreach ADO enumerator to process one row of the recordset at a time. The Foreach ADO enumerator saves the value from each column of the current row into a separate package variable. Then, the tasks that you configure inside the Foreach Loop container read those values from the variables and perform some action with them.61. Delay Validation, Forced ExecutionDelay Validation: Validation take place during the package execution.
Early Validation: Validation take place just before the package execution.62. Transfer Database Taskused to move a database to another SQL Server instance or create a copy on the same instance (with different database name). This task works in two modes: Offline, Online.
Offline: In this mode, the source database is detached from the source server after putting it in single user mode, copies of the mdf, ndf and ldf files are moved to specified network location. On the destination server the copies are taken from the network location to the destination server and then finally both databases are attached on the source and destination servers. This mode is faster, but a disadvantage with mode is that the source database will not available during copy and move operation. Also, the person executing the package with this mode must be sysadmin on both source and destination instances.Online: The task uses SMO to transfer the database objects to the destination server. In this mode, the database is online during the copy and move operation, but it will take longer as it has to copy each object from the database individually. Someone executing the package with this mode must be either sysadmin or database owner of the specified databases.
63. Transfer SQL Server Object Task
Used to transfer one or more SQL Server objects to a different database, either on the same or another SQL Server instance. You can transfer tables, views, Indexes, stored procedures, User defined functions, Users, Roles etc.